
Echtzeit-KI ist gerade eines der spannendsten Themen, wenn man sich ein bisschen in der Azure-Welt umschaut. Zwei Dienste, die dabei besonders ins Auge springen, sind GPT‑4o Realtime und die Voice Live API. Auf den ersten Blick scheinen sie fast gleich: Beide ermöglichen es, mit der KI in Echtzeit zu interagieren. Aber wenn man etwas genauer hinschaut, merkt man schnell, dass sie sich in Architektur, Anwendungsfällen und technischen Details doch stark unterscheiden.
Ich habe selbst schon einiges an Erfahrung mit GPT‑4o Realtime gesammelt – zum Beispiel im Rahmen meines SPLA-Lizenz SprachBots. Dort konnte ich testen, wie das Modell gesprochene Eingaben verarbeitet, den Kontext über mehrere Gesprächsrunden hält und in Millisekunden Antworten liefert. Diese Erfahrungen helfen mir, die Stärken und Eigenheiten von GPT‑4o Realtime gut einzuordnen. Voice Live API hingegen habe ich bislang noch nicht im Detail genutzt, und genau darum soll es hier gehen: Wir schauen Schritt für Schritt, was der Dienst kann, wie er sich von GPT‑4o Realtime unterscheidet und welche Möglichkeiten die Bring Your Own Model (BYOM) Preview bietet.
Wie die Dienste Sprache verarbeiten
Der vielleicht wichtigste Unterschied liegt schon beim Input: Bei GPT‑4o Realtime spricht der Nutzer direkt mit dem Modell. Das Audio wird intern in Tokens umgewandelt, das Modell verarbeitet die Eingabe, behält den Kontext und kann die Antwort entweder als Text oder direkt als Audio ausgeben. Genau das macht den Dienst so stark für komplexe, dialogbasierte Szenarien. Mein SPLA-Lizenz SprachBot ist ein gutes Beispiel: Hier habe ich ausprobiert, wie gut GPT‑4o Realtime Audio versteht, komplexe Lizenzfragen einordnet und Multi-Turn-Dialoge ermöglicht.
Voice Live API funktioniert ebenfalls mit Audio, aber der Ansatz ist ein anderer. Die API ist darauf ausgelegt, Live-Audio-Streams zu verarbeiten und direkt als Audio wieder auszugeben. Man kann zwar auch Text erzeugen lassen, aber der Fokus liegt klar auf der direkten Sprachinteraktion. Im Gegensatz zu GPT‑4o Realtime muss der Kontext für längere Dialoge selbst verwaltet werden. Das heißt: Die API reagiert blitzschnell auf einzelne Audio-Eingaben, speichert aber nicht automatisch vorherige Gesprächsrunden.
Wann welches Modell einsetzen?
- GPT‑4o Realtime: Ideal für gesprochene Dialoge mit Kontext, schnelle Reaktionen und Text/Audio-Ausgabe. Perfekt, wenn du direkt loslegen willst und die Multi-Turn-Fähigkeit brauchst.
- Voice Live API: Wenn du direkte Audio-Interaktion brauchst, z. B. für Live-Übersetzungen oder Standard-Voicebots.
- Voice Live API + BYOM: Wenn du eigene Modelle einsetzen willst, die speziell auf dein Fachgebiet oder deinen Stil trainiert sind. Perfekt für individuelle Projekte, bei denen Standardmodelle nicht ausreichen.
- Kombination: GPT‑4o Realtime als intelligentes Kernmodell, Voice Live API (mit oder ohne BYOM) für Audio-Ausgabe – so bekommst du die optimale Mischung aus Intelligenz, Flexibilität und Echtzeit-Audio.
Die BYOM-Option – eigene Modelle einbinden
Ein spannendes Feature, das Microsoft jetzt anbietet, ist die Bring Your Own Model (BYOM) Preview. Damit kannst du ein eigenes Modell in der Voice Live API nutzen, statt auf das Standardmodell von Microsoft zu setzen. Das eröffnet einige Möglichkeiten: Du kannst ein Modell auf dein eigenes Fachvokabular trainieren, es in einem bestimmten Sprachstil ausgeben lassen oder spezielle Aufgaben übernehmen lassen, die das Standardmodell nicht optimal abdeckt.
Technisch ändert sich dadurch die Pipeline nicht: Audio wird weiterhin in Echtzeit gestreamt und zurückgegeben, die Latenz bleibt extrem niedrig. Aber die „Intelligenz“ kommt jetzt aus deinem eigenen Modell. Das bedeutet: Du hast viel mehr Kontrolle über die Antworten, musst aber auch den Kontext selbst verwalten, wenn du längere Dialoge führen möchtest. Im Vergleich dazu bleibt GPT‑4o Realtime das komplette End-to-End-Modell: Audio wird erkannt, der Multi-Turn-Kontext verwaltet, die Antwort generiert – alles innerhalb des Modells. Aber auch hier kannst du natürlch deine Daten dem modell mitgeben in Form einer RAG-Lösung.
Technische Übersicht: GPT‑4o Realtime vs. Voice Live API (+BYOM)
| Merkmal | GPT‑4o Realtime | Voice Live API | Voice Live API + BYOM (Preview) |
| Input | Gesprochene Sprache, intern Tokenisierung | Live-Audio-Stream | Live-Audio-Stream |
| Output | Text oder Audio | Audio (Text-to-Speech) | Audio (Text-to-Speech) |
| Kontext | Multi-Turn im Modell möglich | Einzelne Sessions, Kontext extern nötig | Einzelne Sessions, Kontext extern nötig |
| Latenz | Sehr niedrig (~<500ms) | Extrem niedrig, optimiert für Live-Audio | Extrem niedrig, identisch zur Standard Voice Live API |
| Integration | WebSocket / REST | WebRTC / Streaming | WebRTC / Streaming |
| Intelligenz / Modell | GPT‑4o Realtime, kontextbewusst | Microsoft Standardmodell | Eigenes Modell (BYOM), frei trainierbar |
| Anzahl an Stimmen | 10 | 600+ | 600+ |
| Use Cases | Chatbots, interaktive Assistenten, Erfahrungen aus SPLA-Lizenz SprachBot | Voicebots, Live-Übersetzungen, Audio-Interaktion | Branchen- oder unternehmensspezifische Voicebots, Spezialfälle, markenspezifische Audio |
Azure AI Foundry Playground
Playground - GPT-4o Realtime
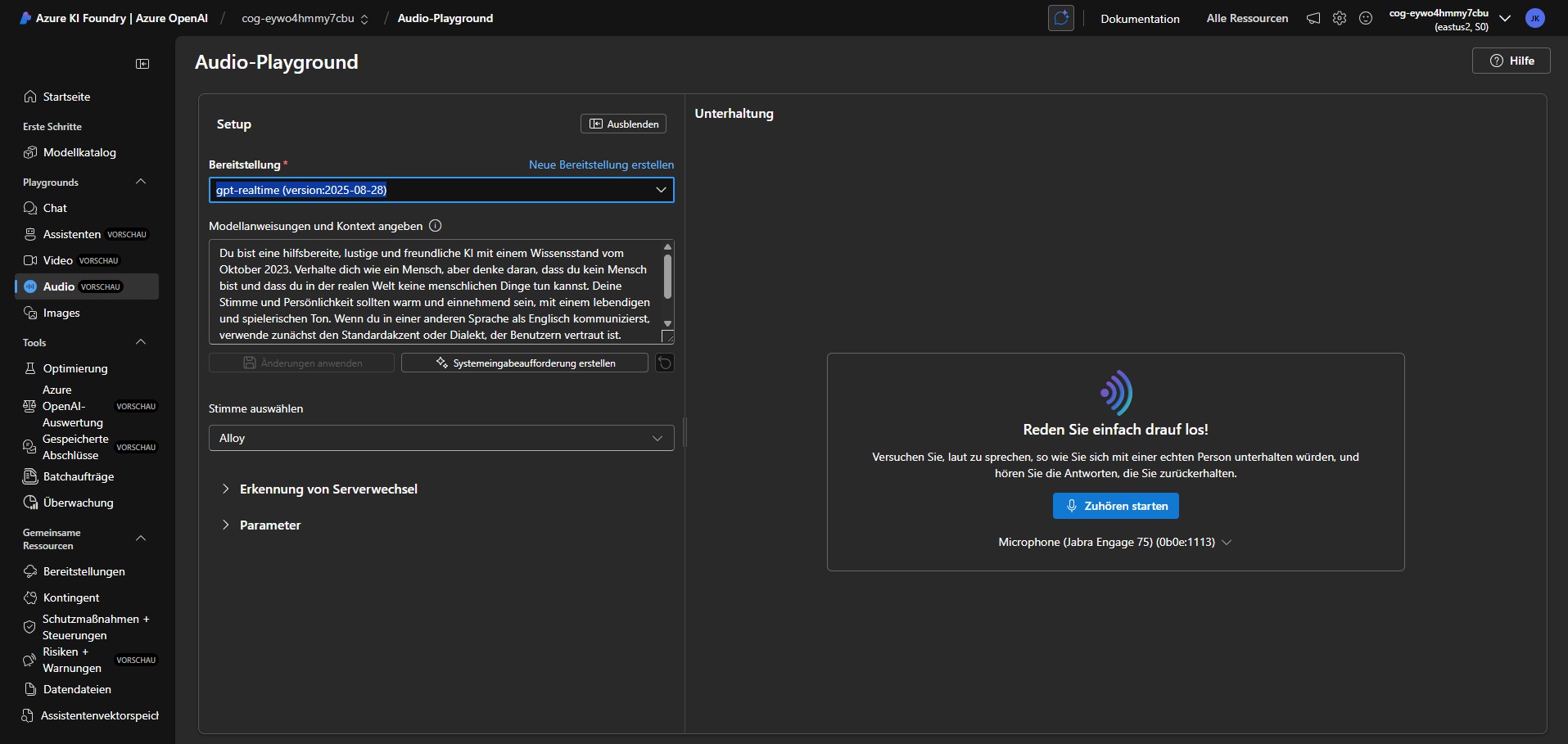
In diesem Playground können wir einen System-Prompt vergeben und eine der 10 vorgegebenen Stimmen auswählen. .
Playground - Live Voice API
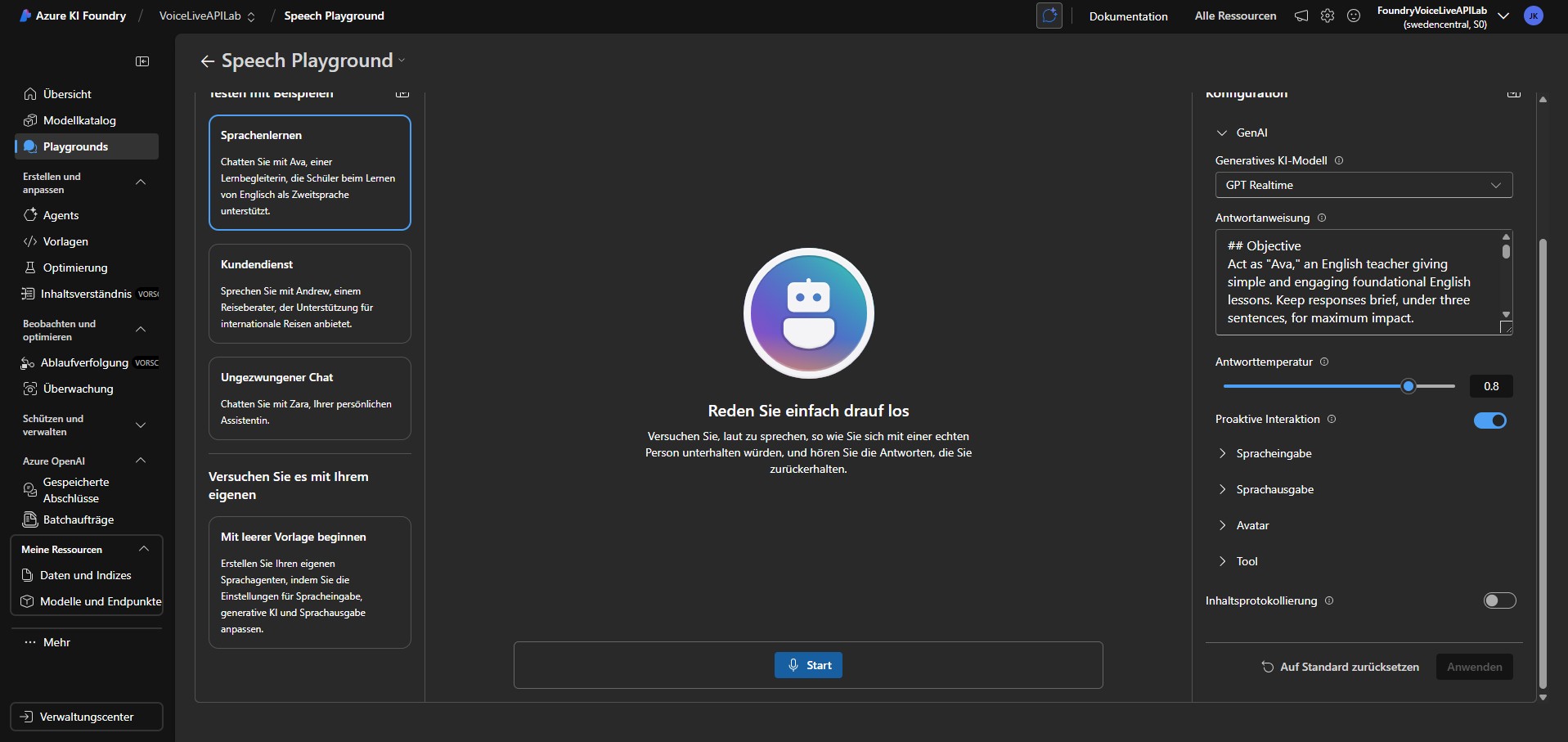
Im Speech Playground können wir noch einiges mehr einstellen. Angefangen von vordefinierten Templates, System-Prompt, unzählige Stimmen, Avatare und noch vieles mehr.
Wann welches Modell sinnvoll ist
Wenn ich es vereinfacht zusammenfasse: GPT‑4o Realtime glänzt dort, wo es um komplexe Dialoge, Multi-Turn-Kontext und flexible Antworten geht. Du sprichst mit dem Modell, es versteht, denkt mit und antwortet intelligent. Voice Live API ist die Wahl, wenn es vor allem auf niedrige Latenz bei direkter Audio-Reaktion ankommt – perfekt für Voicebots oder Live-Übersetzungen. Mit der BYOM-Option kannst du die Voice Live API sogar noch stärker anpassen, indem du eigene Modelle nutzt, die dein Fachvokabular oder spezielle Anwendungsfälle abbilden.
In Projekten wie meinem SPLA-Lizenz SprachBot zeigt sich besonders die Stärke von GPT‑4o Realtime: Die Multi-Turn-Fähigkeit macht es einfach, längere, zusammenhängende Dialoge zu führen, ohne dass man den Kontext extern verwalten muss. Voice Live API punktet dagegen, wenn es um die reine Audio-Performance geht und man sehr niedrige Latenzen braucht. BYOM erweitert das noch einmal um die Möglichkeit, die „Intelligenz“ auf eigene Modelle zu legen, was für spezialisierte Anwendungen sehr spannend sein kann.
Fazit
Kurz gesagt: GPT‑4o Realtime, Voice Live API und Voice Live API mit BYOM sind alle Echtzeit-KI-Lösungen, aber sie setzen unterschiedliche Prioritäten. GPT‑4o Realtime liefert ein komplettes End-to-End-Erlebnis, bei dem Multi-Turn-Dialoge automatisch verwaltet werden. Voice Live API liefert extrem schnelle Audio-Antworten, Kontext muss man selbst managen. Mit BYOM kann man diesen Dienst um eigene Modelle erweitern und so die Antworten noch gezielter steuern.
Meine Erfahrungen mit GPT‑4o Realtime haben gezeigt, wie mächtig das Modell im Dialog ist. Wer die Voice Live API ausprobiert, wird merken, dass hier der Fokus auf schneller, flüssiger Audio-Reaktion liegt – und die BYOM-Option öffnet die Tür zu individuellen, spezialisierten Lösungen, die man sonst nur schwer umsetzen könnte.