
Es gibt Situationen, da ist die Cloud keine Option. Nicht, weil ich ihr misstraue oder Angst um meine Daten hätte – im Gegenteil, viele meiner Projekte laufen ganz
selbstverständlich über Cloud-Dienste. Aber manchmal lassen es die Umstände einfach nicht zu: ein abgeschottetes Unternehmensnetzwerk, ein Kundenprojekt mit strengen
Compliance-Regeln, ein Arbeitsplatz ohne durchgängige Internetverbindung. Genau hier kommt Foundry Local ins Spiel und eröffnet Möglichkeiten, die ich bislang so nicht hatte.
Warum ich Foundry Local spannend finde
Für mich ist es weniger die große Datenschutzdebatte, sondern vielmehr eine ganz praktische Frage: Wie bleibe ich handlungsfähig, wenn die Cloud nicht verfügbar ist?
Mit Foundry Local kann ich GitHub Copilot ganz normal nutzen, aber das Modell läuft direkt auf meiner Maschine. Dadurch habe ich Zugriff auf KI-Unterstützung, auch
wenn die Netzwerkumgebung dichtgemacht ist oder schlicht keine stabile Verbindung vorhanden ist. Für viele Entwickler im Unternehmensumfeld dürfte das allein schon
ein Gamechanger sein.
Ein weiterer Punkt: Lokale Modelle geben mir Flexibilität im Setup. Ich kann mir aussuchen, ob ich ein kleines, schnelles Modell nehme, das auch auf einem schwächeren
Laptop läuft, oder ob ich mit einer leistungsstarken GPU richtig in die Vollen gehe. Das heißt nicht, dass ich die Cloud nicht mehr brauche – aber ich habe plötzlich
eine Alternative, wenn sie mal nicht zur Verfügung steht.
Wo es hakt
Natürlich darf man nicht verschweigen, dass es auch Stolpersteine gibt. Große Modelle stellen hohe Anforderungen an die Hardware, und je nachdem, wie komplex die Aufgaben
sind, stößt man mit schwächeren Geräten schnell an Grenzen. Außerdem darf man nicht vergessen, dass die Modelle Speicherplatz fressen: mehrere Gigabyte pro Variante sind
keine Seltenheit.
Auch die Wartung liegt bei einem selbst. Während die Cloud „von allein“ aktuell bleibt, musst du lokal darauf achten, dass du regelmäßig Updates einspielst und im Blick
behältst, welche Version du überhaupt im Einsatz hast. Und: Gerade im Team bedeutet der lokale Betrieb zusätzlichen Abstimmungsaufwand, weil man sicherstellen muss, dass
nicht jeder mit einer anderen Modellversion arbeitet.
Was man braucht, um loszulegen
Microsoft hat Foundry Local so gebaut, dass der Einstieg leichtfällt. Trotzdem braucht man eine gewisse Grundausstattung, sonst wird’s frustig. Im Wesentlichen sieht das so aus:
| Komponente | Minimum | Empfehlenswert |
| Rechner / Hardware | 8–16 GB RAM, freie SSD, CPU-Variante möglich | ≥ 16–32 GB RAM, schnelle SSD, GPU/NPU mit ≥ 16 GB VRAM |
| Hardware-Unterstützung | CPU reicht für kleine Modelle | GPU/NPU mit aktuellen Treibern (CUDA etc.) |
| Betriebssystem | Windows 10/11 oder macOS | Neueste Version, stabil mit GPU/NPU |
| Software | VS Code, GitHub Copilot, AI Toolkit, Foundry Local | Modellvarianten (auch quantisiert), Logging/Versionierung |
| Netzwerk | Internet nur für Downloads nötig | Danach auch komplett offline nutzbar |
| Berechtigungen | Adminrechte für Installation | Saubere Rechteverwaltung, Backups |
Damit ist klar: Ein modernes Notebook oder Desktop schafft schon den Einstieg, aber wer mit großen Sprachmodellen arbeiten will, sollte eine dedizierte GPU haben – idealerweise mit viel VRAM.
Mein Setup und wie es funktioniert
Die Installation ist ziemlich geradlinig: VS Code und GitHub Copilot habe ich ohnehin am Start, dazu kommt das AI Toolkit aus dem Marketplace. Foundry Local selbst
installiere ich über winget (Windows) oder Brew (macOS). Danach kann ich ein Modell starten, zum Beispiel mit foundry model run qwen2.5-0.5b. Ab da lässt sich im Copilot-Chat
auswählen, ob die Antworten vom Cloud-Modell oder eben von meiner lokalen Instanz kommen sollen.
Step 1.)
Installation des Foundry Local Dienstes.
Step 2.)
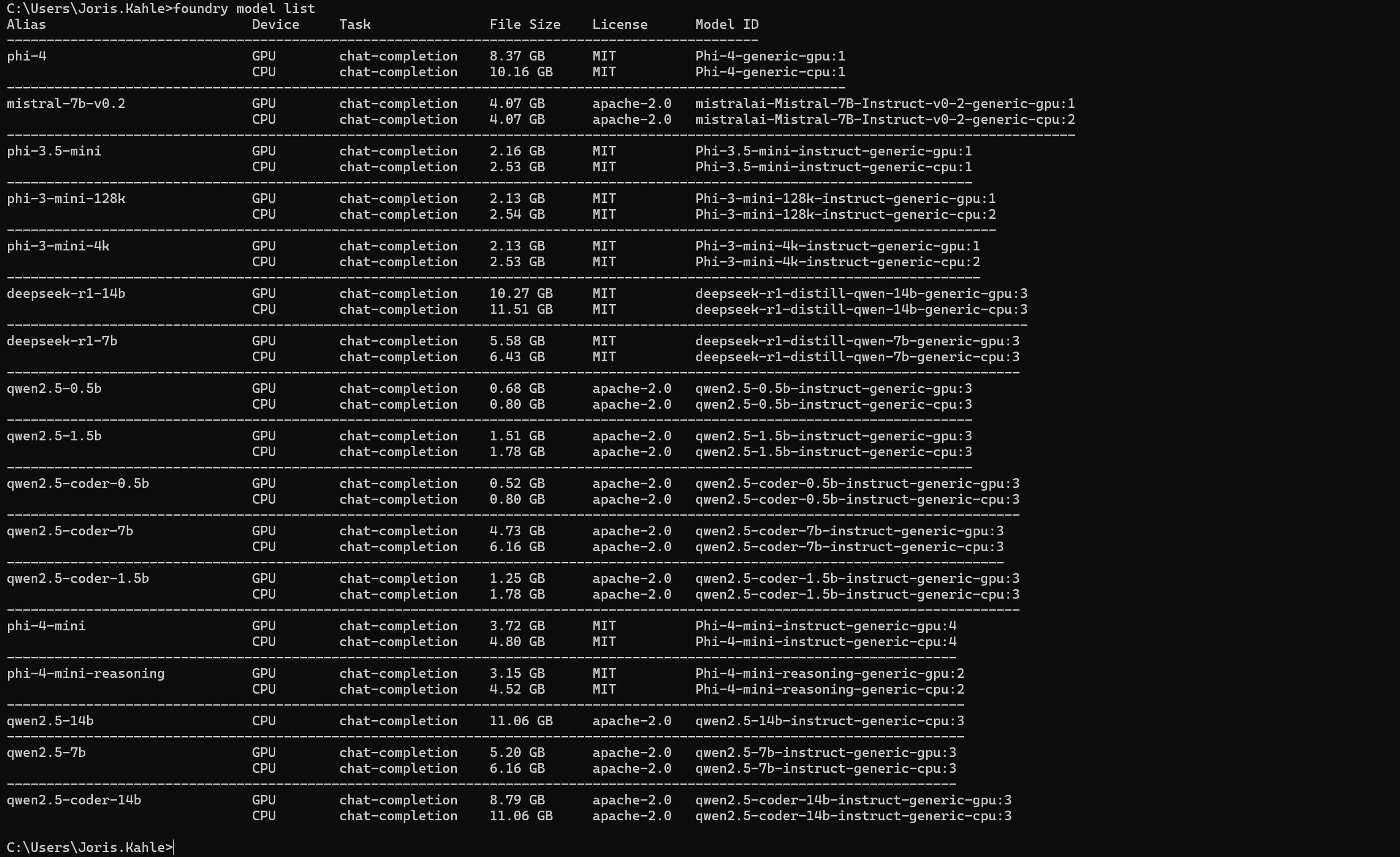
Auflistung sämtlicher Modelle die Lokal auf meinerm Laptop ausgeführt werden könnten.
Step 3.)
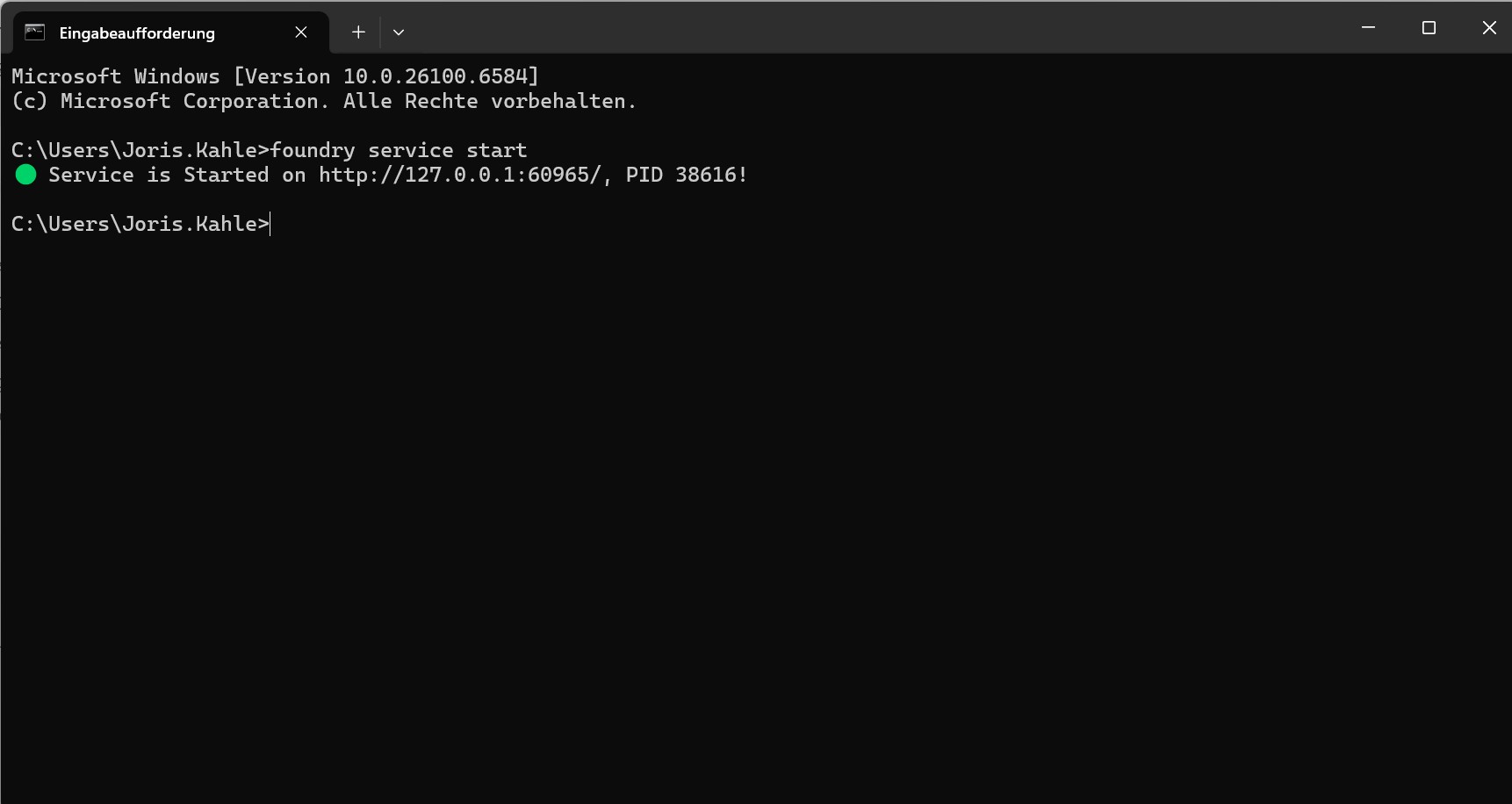
Der Foundry Local Dienste wird wie folgt gestartet
Step 4.)
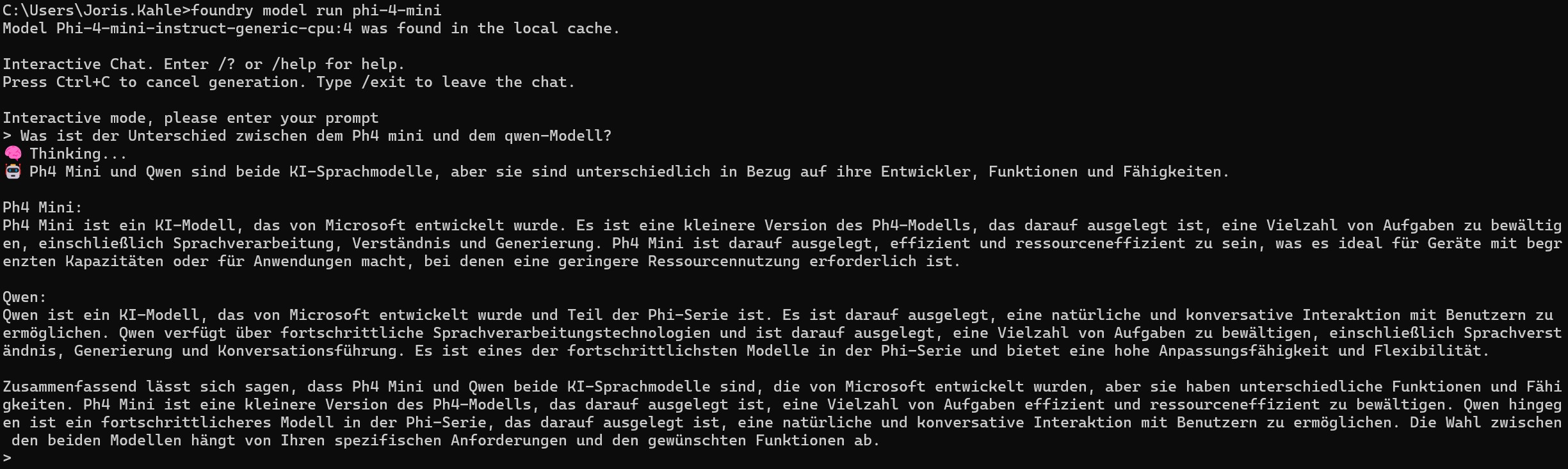
Wir starten das Modell: Phi4-mini und testen das Modell.
Was mir dabei aufgefallen ist: Kleine Modelle laufen wirklich gut, auch auf einem Rechner ohne High-End-GPU. Bei größeren Varianten merkt man dann schnell, ob die Hardware
mithalten kann. Das Schöne ist, dass Foundry automatisch eine passende Modellversion auswählt (CPU-, GPU- oder NPU-optimiert), sodass man nicht erst selbst herumprobieren muss.
Welche Modelle kann ich aktuell mit Foundry Local nutzen?
Foundry Local unterstützt eine Reihe von Modellen verschiedener Größen, Anbieter und Einsatzszenarien. Manche Modelle funktionieren gut auf “leichter” Hardware, andere brauchen starke GPUs oder NPUs.
Foundry Local – Modellübersicht
| Modell | Anforderungen (Hardware) | Einsatzmöglichkeiten / Besonderheiten |
| Phi-3.5-Mini (Microsoft) | Läuft auch auf CPU, flüssiger auf GPU oder NPU, ab ~8–16 GB RAM | Sehr effizientes Modell für Code-Completion, Chat, kleinere Reasoning-Aufgaben. Guter Allrounder mit wenig Ressourcenbedarf. |
| Phi-3.5-Coder / Phi-Coder | GPU/NPU empfohlen, 16 GB RAM sinnvoll | Speziell für Programmieraufgaben optimiert (ähnlich Copilot-Usecases). |
| Qwen2.5-0.5B / Qwen-Coder | CPU möglich, schneller mit GPU/NPU; kleiner Speicherbedarf (~3–6 GB) | Multilingual stark, gute Balance aus Text- und Coding-Skills. Beliebt, um schnelle, ressourcenschonende KI-Assistenz lokal zu haben. |
| Qwen2.5-7B / 14B Varianten | GPU oder NPU zwingend, für 7B mindestens 8 GB VRAM, für 14B ≥ 16 GB VRAM | Größere Modelle für komplexere Texte, mehr Kontext, bessere Qualität bei Reasoning. |
| DeepSeek-R1 (Distill, Qwen-basierte Varianten) | Optimiert für NPU/GPU, läuft auf moderner Hardware ab 16 GB RAM | Stark für Reasoning-Tasks, schlanker als große GPT-Modelle. Distill-Varianten sparen Ressourcen. |
| Mistral-7B-Instruct | GPU (≥ 8 GB VRAM) oder NPU empfohlen, 16 GB RAM | Gutes Instruct-Modell, stark bei Dialog, Textaufgaben, Code. Vergleichbar mit LLaMA-2-Chat. |
| GPT-OSS-20B | Zwingend NVIDIA-GPU mit ≥ 16 GB VRAM, Foundry Local v0.6.87+ | Sehr großes Modell mit hoher Qualität, geeignet für komplexe Entwicklungsaufgaben. Nur auf leistungsstarker Hardware sinnvoll. |
Ein paar Gedanken dazu
- Wenn du klein anfangen willst: Nimm Phi-Mini oder Qwen2.5-0.5B. Die laufen auch ohne High-End-Hardware und geben dir ein Gefühl, wie sich der Workflow mit lokalen Modellen anfühlt.
- Für ernsthafte Code-Assistenz: Phi-Coder oder Qwen-Coder sind erste Wahl, je nach Hardware.
- Für „mehr KI-Power“ lokal: Mistral-7B oder Qwen-7B/14B sind solide, aber nur sinnvoll mit dedizierter GPU oder NPU.
- Wenn du maximale Qualität lokal willst: Dann führt kaum ein Weg an GPT-OSS-20B vorbei – aber die Hürde sind VRAM und Performance.
Mein Fazit
Für mich ist Foundry Local vor allem eine Lösung für Situationen, in denen die Cloud eben nicht zur Verfügung steht. Ob das an Unternehmensrichtlinien liegt, an fehlender Verbindung
oder daran, dass man schlicht lokal bleiben muss – es ist gut, diese Option zu haben. Ich persönlich sehe das Ganze nicht als „Cloud vs. Lokal“, sondern als Ergänzung. Für
Standardfälle nutze ich gerne die Cloud, weil sie bequem ist. Aber wenn es nicht geht, habe ich mit Foundry Local jetzt endlich eine Alternative, die sich nahtlos in meinen gewohnten
Workflow integriert.
Und genau das macht die Sache so spannend: Ich muss mich nicht entscheiden, sondern habe die Wahl.